






.BooyBYol.svg)








realfast labs | From the Labs
4 surprising things we learned testing agents on Agentforce
We ran into some unexpected quirks while testing Salesforce agents. Here's what you need to know before starting.

Salesforce’s new Agentforce Testing Center is an exciting development for anyone building Agents on Agentforce. It promises a clean way to automate test cases, verify topic and action classification, and ensure the final responses match our expectations. But in practice, we’ve made a few surprising discoveries — some that can trip you up if you’re not thorough.
You build what seems like the perfect AI agent, run it through testing, and… things get funky. That’s exactly what happened to us, and I thought I’d share some surprising things we discovered along the way.
The short version (For those in a hurry)
If you’re skimming this during your coffee break, here’s what we found out the hard way:
-
Topic classification doesn’t always work as expected - and sometimes that’s fine
-
Sometimes you’ll get the right answer for seemingly wrong reasons
-
Tests can pass with flying colours while giving totally made-up information
-
When running the same test twice, don’t be surprised if you get different results
Intrigued? Grab another coffee and let’s dive into the details.
How it started
We started with a custom-built agent on Salesforce, complete with topic definitions (e.g., “Sales Inquiry,” “Product Information”) and corresponding actions (e.g., “Schedule a Call,” “Fetch Information”).
To ensure robust testing coverage, we created a CSV file of test cases:
-
User Input (what the user says)
-
Expected Topic (what topic would this request be mapped to)
-
Expected Action (what action would be called by the agent)
-
Expected Response (the gist of what the agent response should look like)
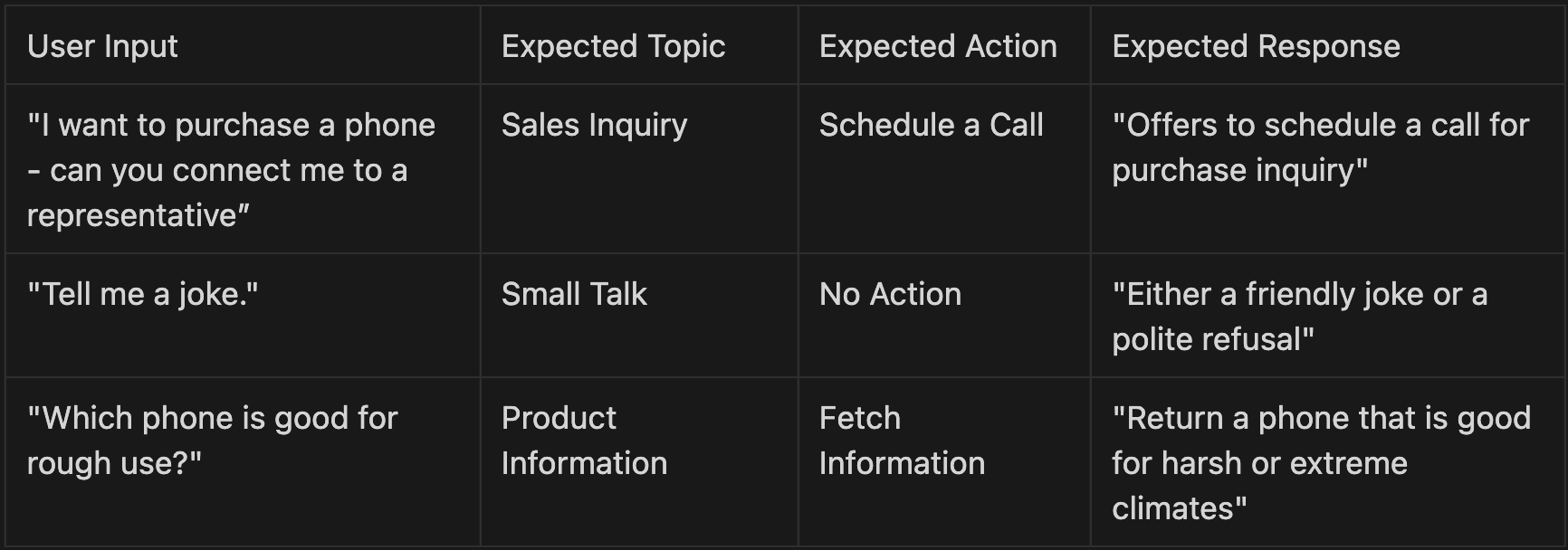
We uploaded this CSV to the Testing Center and ran multiple test suites to observe how topics were classified and whether the actual answer matched our expectations.
What we found
1. Topic classification can go wrong. Here’s what you can do about it.
One of the biggest takeaways was that topic classification can sometimes be off, especially for questions that don’t neatly match any pre-defined instruction. For example:
-
Out-of-scope queries: “Tell me a joke” or “What’s your favourite colour?”
-
Ambiguous queries: “I’m thinking about buying a phone but not sure what.”
When the agent’s description does not clearly address these corner cases, the Testing Center may randomly assign them to a fallback or a “best guess” topic. Sometimes it’s Small Talk, other times it lands in Off-Topic.
Takeaways
- Refine your agent: Update your agent’s description and scope with explicit examples (both typical and out-of-scope user inputs) so the agent knows exactly what to do.
Consider this example of handling an ambiguous query like “I’m thinking about buying a phone but not sure what.” This type of query could be misclassified as Product Information (since they’re asking about phones), Sales Scheduling (since they might need consultation), or even fall into a generic topic. Instead of accepting this ambiguity, you could redesign your agent with more specific topics:
-
Product Discovery: To understand user preferences and requirements
-
Product Information: To provide detailed specifications and comparisons
-
Sales Consultation: To schedule a personalized consultation call
This structured approach transforms a potentially confusing query into a clear conversation flow, ensuring consistent topic classification and better user experience.
- Reflect on real-world data: See how people use the agent. Incorporate that feedback into your agent to reduce “random” classification.
2. You can get the correct output even when the topic classification is incorrect.
Surprisingly, in some test runs, the final response was still correct — even though the topic was incorrectly classified. For instance:
-
User Input: “I’m ready to buy—set up a call with a rep.”
-
Expected Topic: “Sales Inquiry”
-
Actual Topic: “Small Talk” (due to some classification hiccup)
-
Final Answer: “Sure, I can schedule a call. May I have a contact number?”
Despite labelling it as Small Talk, the agent took the correct action — Schedule a Call — and produced the right final text. This indicates the underlying conversation logic sometimes overrides a mislabel if other signals in the user input are strong enough.
Takeaways
- Don’t rely solely on topic classification as your success metric. Optimise for the actual response, as that’s what your customers will see.
- Fine-tune your agent descriptions if you see consistent misclassifications. Even if the system recovers, you want predictable classification for easier maintenance.
Here’s an example of improving topic classification.
Initial agent description:
“Activate Sales Inquiry when you detect an intent to book a meeting.”
This could lead to misclassification since agents might miss various ways customers express meeting intent.
Improved agent description:
“Activate Sales Inquiry when you detect an intent to book a meeting. Look for any phrasing that suggests:
-
Wanting to schedule a conversation
-
Interest in discussing further
-
Request for a call or consultation
-
Desire to learn more through direct communication”
This improved description is more comprehensive as we always explain how to detect intent and hence reducing the chances of misclassification of topics.
3. Tests can pass with flying colours while giving totally made-up information.
Test passes don’t always guarantee factual accuracy. Understanding how the Testing Center evaluates responses is crucial for reliable testing. The Testing Center offers ways to specify your expected response — essentially, what a right answer looks like and the actual right answer.
Scenario 1: You get the right answer
Say you specify the actual details of the phone. The Testing Center will check if the agent’s response matches the specified details. Straightforward.
Scenario 2: You get what only looks like the right answer
Say you specify that the expected response should be details of a phone. The Testing Center gauges if the agent’s response semantically represents the details of a phone. It does not focus on verifying if the details are correct.
Wait what?
Here’s an example of a passed test that’s incorrect:
-
User Input: “Which phone is good for extreme weather?”
-
Expected Topic: “Product Information”
-
Expected Action: “Fetch Information”
-
Expected Response: “Phones that are good in harsh climates”
-
Actual Chatbot Response: “Phone XP has a protective glass, tested for -100°C temperatures.”
The Testing Center sees “This mentions protective glass and extreme climates, so it’s probably correct.” But the phone’s actual specs are nowhere near that. The chatbot hallucinated an unrealistic temperature rating. The Testing Center might still mark it as a pass because the structure is correct: it’s giving a phone and referencing extreme climates.
Takeaways
Choose your expected response type strategically.
-
Use specific, factual responses (e.g., exact phone specs) when testing product details, technical specifications, or any factual information where hallucination would be problematic. Like in our example, instead of “Phones that are good in harsh climates”, we should’ve used “Phone XP with protective glass rated for sub-zero temperatures” as the expected response.
-
Use semantic response patterns (what the right answer “looks like”) for conversational flows or generic tasks where multiple valid responses exist — like meeting bookings (“Response should include date, time, and confirmation”), general greetings, or collecting user preferences.
This way, you get the best of both worlds — strict validation where accuracy matters most, and flexible testing where variation is acceptable.
4. Running the same test twice? Don’t be surprised if you get different results.
During our repeated test runs in the Testing Center, we stumbled upon a fascinating pattern of how the assigned topic changes across different testing runs of the same inputs.
-
Random or Off-Topic Inputs
-
Example: *“Tell me a joke!”*
-
Finding: The chatbot would sometimes classify this as Small Talk, sometimes even Off-Topic — all while returning a broadly similar final response.
-
Reasoning: Because the user request doesn’t strongly match any of the pre-defined “relevant” topics, the agent seems to “guess” based on the closest available bucket. This can lead to higher variance across multiple test runs for the same input.
-
-
Relevant or In-Scope Inputs
-
Example: “I’d like to purchase a phone, but first tell me its battery life.”
-
Finding: While there can still be minor variations (e.g., classifying it as Sales Inquiry or Product Comparison), the chatbot tends to be far more consistent in how it labels these user requests, thanks to clearer signals in the prompt.
-
Reasoning: Well-defined instructions (like “Sales Inquiry” or “Product Comparison”) help the agent lock onto a stable topic classification if the user’s intent strongly matches one (or more) of those categories.
-
Takeaways
-
If you notice significant variance for inputs you do care about, fine-tune your agent descriptions.
-
Off-topic queries are common in real-world conversations. You can modify the standard topics like ‘Off Topic’ to return clear messages like “I apologize, but I can only help with questions about our products and services. Could you please rephrase your question?” This ensures consistent handling of out-of-scope queries and reduces surprises.
Putting it all together
After tonnes of iteration on testing our agents in Salesforce’s Testing Center, here’s what it all comes down to: Agentforce is a powerful thing, but it’s not perfect. And that’s okay – as long as you know what to watch out for.
Here are the key takeaways
-
Topic classification may be wrong: Refine your agent’s instructions to handle edge cases and reduce confusion.
-
Wrong classification ≠ Wrong answer: Sometimes the agent recovers internally, which is great — but you still want consistent classification for clarity and debugging.
-
Hallucinations are Real: Even if your test “passes,” the answer might be factually incorrect. Use domain-specific checks to catch these.
Focus on
-
Making your agent instructions crystal clear
-
Testing thoroughly with real-world scenarios
-
Double-checking factual information
-
Building in proper guardrails for out-of-scope queries
Most importantly, don’t treat test results as the final word. They’re a tool to help you build better agents, not a guarantee of perfect performance.
Need Help?
Still have questions about building and testing agents? Feel free to reach out to our team. We are happy to share more details about what we’ve learned along the way.